
What Is Computer Vision?
When your smartphone recognizes your face, your car avoids drifting from its lane, or your social media automatically tags friends in photos, you're witnessing the silent power of Computer Vision. While chatbots and AI writing tools grab headlines, this remarkable technology works behind the scenes, fundamentally transforming how machines perceive and interpret our visual world.
Computer Vision represents AI's eyes on the world—technology that enables machines to extract meaning from images and videos with almost human-like understanding. It's the difference between a camera that merely captures pixels and a system that comprehends what those pixels represent: faces, objects, text, motion, and the complex relationships between them.
From the smartphone in your pocket to medical imaging systems detecting early-stage cancer, Computer Vision has quietly evolved into one of the most consequential technologies of our time. Its applications extend into nearly every industry—enhancing safety, enabling automation, and unlocking insights previously invisible to the human eye.
Yet despite powering countless daily interactions with technology, Computer Vision remains largely unrecognized by the very people who benefit from it most. Let's pull back the curtain on this transformative technology and explore how it's reshaping our relationship with the visual world.
Navigating the AI Landscape: Understanding the Technologies
In today's technology world, buzzwords fly fast and furious. Before diving deeper into Computer Vision, let's decode the essential terminology that shapes modern artificial intelligence.
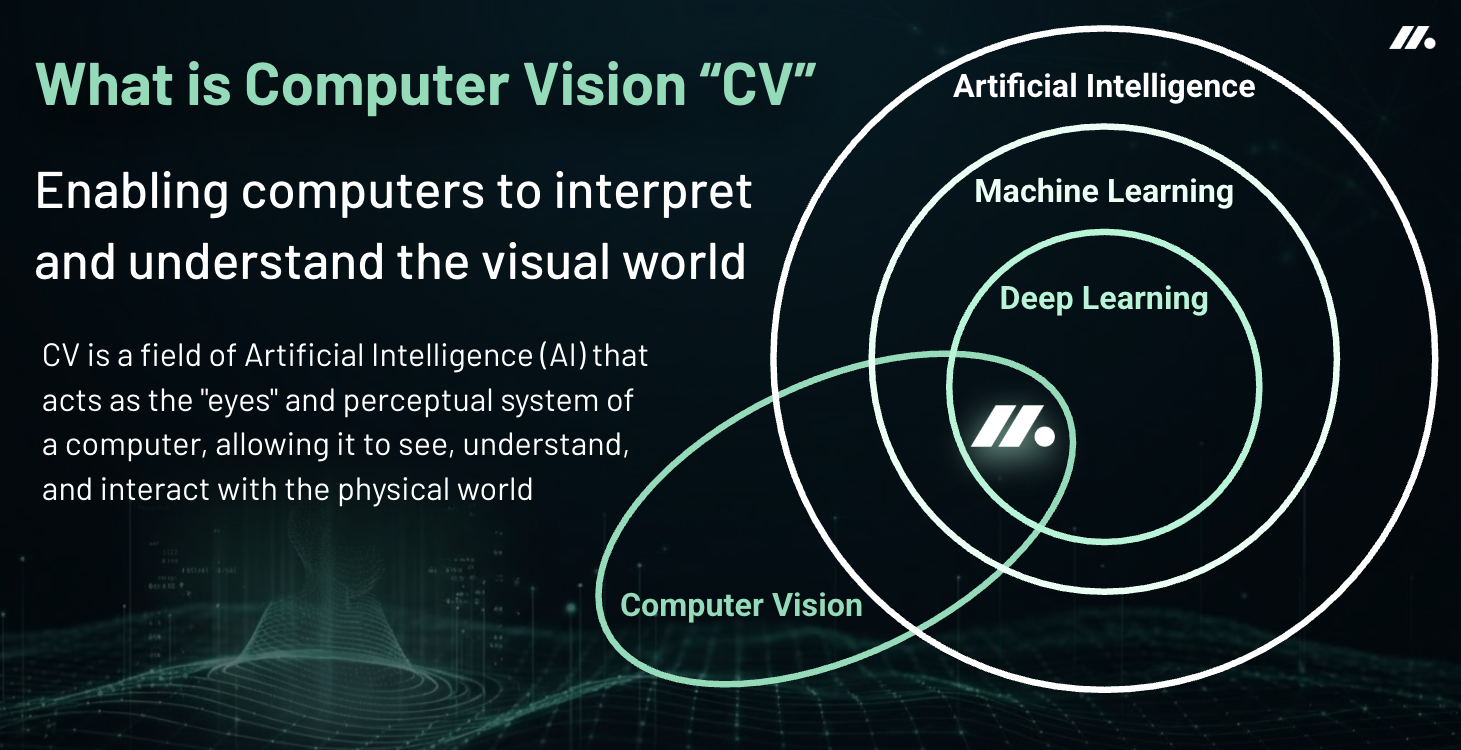
The AI Family Tree
Artificial Intelligence represents the grand umbrella—technology designed to perform tasks that typically require human intelligence. Within this realm, three major branches have emerged, each with distinct yet interconnected purposes:
Machine Learning serves as the fundamental engine, enabling systems to identify patterns, learn from data, and improve over time without explicit programming. Rather than following rigid instructions, ML systems evolve through experience—much like humans do.
The recent AI revolution stems largely from advances in Deep Learning—a specialized approach within Machine Learning that employs neural networks with multiple layers to process information.
Natural Language Processing (NLP) gives machines the ability to comprehend and generate human language, powering everything from the voice assistant on your phone to sophisticated translation services that bridge communication gaps across cultures.
Large Language Models (LLMs) like GPT and Claude are a subset of NLP: they are advanced AI models (like GPT-4) trained on massive text datasets to generate, summarize, and understand natural language. LLMs use deep learning and transformer architectures to perform higher-level language tasks, often surpassing traditional NLP models in complexity and capability.
Computer Vision grants machines the gift of sight—the ability to interpret and understand visual information from the world around them, turning pixels into meaningful insights. Identifying objects, tracking movement, and extracting meaning from the visual world.
The most powerful AI systems today combine these capabilities. When an AI application generates an image from your text description or explains what it "sees" in a photograph, you're witnessing the seamless integration of language and visual processing—Computer Vision and Natural Language Processing working in harmony.
How Computer Vision Works
CV has many subfields, roughly aligned around computer vision “tasks”, such as facial recognition, medical image analysis, pose detection, among a host of other specializations. Each CV task turns some aspect of raw visual data into information computers can understand. Some of these important tasks include:
Object Classification often identifies what objects exist in an image and how many there are. For example, "there are two putters and one golf ball."
Object Localization adds location and/or positional information such as the bounding boxes enclosing the objects, or alternatively object size, orientation and center estimates. For example “there is one putter at a 30 degree angle to the right of a ball that is 40 pixels wide”.
Object Detection combines classification and localization to know what objects are in the image and where they are located.
Segmentation provides the most detailed output, determining exactly which pixels belong to each object. This creates precise outlines of objects.
Each task yields progressively more detailed information about what the camera sees. Thanks to deep learning, these systems can be trained to yield more accurate results than ever before. When analyzing motion in sports, CV systems go beyond just tracking 2D image positions—they can measure geometric dynamics, studying how objects move along paths in 3D space. For a golf putt, this includes tracking the arc of the putter's path, how the shaft angle changes during the stroke, and how these geometric patterns affect the ball's roll as it skids and eventually rolls across the green. Understanding these relationships helps connect what the camera sees to the physics that determine performance outcomes.
Meridian's Sport Motion Innovation
Meridian is creating new CV applications, starting with golf putting analysis. Under CTO Cody Phillips, PhD, the company has engineered and trained CV/ML systems that turn smartphone cameras into powerful motion analysis tools.
Dr. Phillips brings over 10 years of CV expertise to Meridian. His research includes state-of-the-art developments in:
Automated object recognition and mapping
3D reconstruction of transparent objects
Shape analysis of symmetrical objects
Mobile motion detection and analysis in real-time
"We're using advanced CV techniques that were once only possible with expensive equipment," explains Dr. Phillips. "Our system can measure putter movement, ball spin, and roll characteristics using just a smartphone."
Meridian's technology makes professional-level motion analysis available to everyday golfers. Players can understand their putting stroke and improve their performance through easy-to-understand feedback and personalized coaching.
By combining the science of computer vision with sports analysis, Meridian helps golfers improve their game in ways that were once available only to professionals with expensive equipment. While putting analysis marks our first application, Meridian's vision extends far beyond golf. The future of Computer Vision at Meridian promises to expand into new domains, ranging from data-driven insights in human sports performance to enabling automation, intelligent systems, and human-machine interaction. As the technology evolves, so too will our capacity to help people gain meaningful insights from visual information.