
Not All Computer Vision Is Created Equal: Teaching Machines to Measure

Visual comparing ball in motion circumference estimations
This is a follow-up to our previous exploration of "What Is Computer Vision?" where we unveiled how this transformative technology works behind the scenes to give machines the gift of sight.
When manufacturing systems automatically measure parts to within thousandths of an inch on production lines, you're seeing advanced technology at work. When medical imaging systems detect tumors in X-rays with surgical precision, or when 3D vision guides robotic arms to pick components from bins, these applications demonstrate something remarkable. These are examples of Computer Vision techniques that go far beyond basic image recognition. They measure what they see with scientific precision.
As Meridian Performance Systems continues leading sports motion analysis, we get asked one question frequently: "Is your technology hard to copy? Could anyone just build an AI tool to do what you're doing?" This question shows a common misunderstanding about artificial intelligence. Every business leader should grasp this concept.
The answer comes down to understanding a key difference. It is one thing to recognize the world, but to measure it is something entirely different. Image Metrology is a Computer Vision application that transforms pixels into precise, meaningful measurements of the real world. It does so by combining physics, geometry, mathematics and machine learning.

A putting Stroke captured via Meridian's Mobile Putting Application
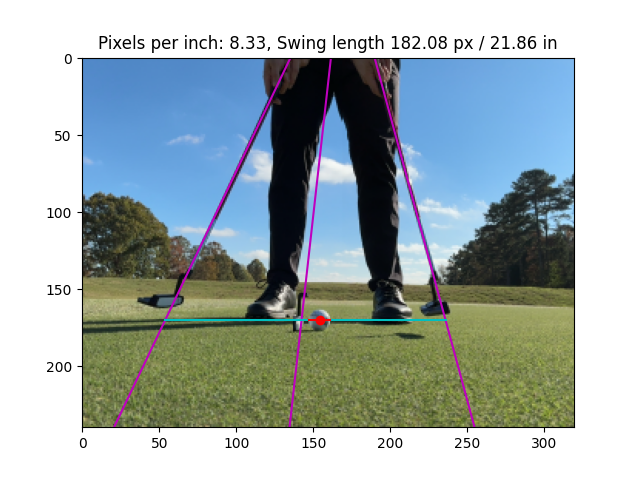
Visualization of Stroke Length calculated through Back-Projection
Beyond Recognition: When Computers Measure What They See
Most people see computer vision in its simplest form: identification. Your photo app recognizes faces. Cars with driving assist detect other cars and obstacles. Security cameras detect people. These systems answer one basic question: "What am I looking at?"
Image Metrology asks a much harder question: "What are the precise measurements of what I'm seeing?"
Here's the difference in practical terms. Basic recognition knows someone is putting a golf ball. Advanced metrology measures that their putter moved through a 14-inch arc at exactly 2.3 feet per second. It calculates that the ball rolled 8.2 feet before slowing down at 1.4 feet per second squared.
This shift from pixels to precise measurements requires solving one of computer vision's hardest problems: back-projection. Picture this scenario. You're looking at a photograph of a building. Now you need to figure out its exact height, width, and distance from the camera.
The computer must reverse-engineer real-world dimensions from a flat, two-dimensional photo. It accounts for camera angle, lens distortion, lighting conditions, and perspective. For golf putting analysis, this means converting club and ball locations from smartphone video into scientifically accurate measurements. Golfers can then use these measurements to improve their performance.
It's the difference between "the computer sees something moving" and "the computer understands exactly how that movement affects performance."
The Vision Transformer Revolution: Teaching Machines to See Like Humans
Traditional computer vision systems use Convolutional Neural Networks (CNNs). This technology examines pictures by scanning small sections at a time. Think of reading a book with a magnifying glass that shows only a few words at once. This approach works fine for basic recognition tasks. But it struggles with complex scenes where relationships between distant elements matter.
Vision Transformers (ViT) represent a major breakthrough in how machines process visual information. Instead of scanning images piece by piece, ViT breaks images into patches. It then analyzes all patches at the same time. Every part of the image connects to every other part.
Think of the difference this way. Traditional systems examine a painting through a keyhole. Vision Transformers see the entire masterpiece at once.
This global understanding proves crucial for golf putting analysis. When a golfer putts, multiple factors influence the outcome. The putter's position matters. So does the ball's location, the green's slope, and even the golfer's stance. Traditional CNNs might identify these elements separately. Vision Transformers understand how they work together as a complete system.
The self-attention mechanism that powers ViT focuses on the most relevant relationships in real-time. During a putting stroke, it might track the putter head's angle, the ball's starting position, and the green's surface characteristics all at once. It understands how changes in one element affect all the others. This complete analysis enables insights that would be impossible with traditional approaches.
The Data Advantage: Why Real-World Diversity Matters
Building effective Computer Vision Metrology systems requires something special. You can't purchase it or quickly assemble it. You need diverse, real-world data that captures the full complexity of actual conditions.
Meridian's training dataset shows this principle perfectly. Version 2 of our system learned from 389 videos. These contained 131,158 carefully annotated frames. Version 3 expanded this foundation. We added 695 more videos and 140,768 newly annotated frames.
But the true power doesn't lie in the quantity. It's in the organic diversity.
Every frame comes from real golfers. They use different clubs and putt on various surfaces. They play under countless lighting conditions from multiple camera angles. This natural variation teaches the AI to handle edge cases. These are unusual but real-world scenarios that would break systems trained on perfect, lab-controlled data.
Consider the complexity involved. Indoor putting versus outdoor greens. Morning shadows versus midday sun. Different smartphone cameras with varying lens characteristics. Putters with different finishes that reflect light differently. A system trained only on controlled data would fail when facing the messy reality of actual use.
This creates a data flywheel effect. Each new user generates more diverse data. This improves the AI's accuracy. A better product attracts more users. This accelerates the data collection cycle. What once took months to annotate and train now takes weeks for improvements. Our advancement rate keeps accelerating.
The Expertise Barrier: Why This Can't Be Copied Quickly
Advanced machine learning architectures combined with classical computer vision techniques require rare expertise. This goes far beyond general AI knowledge.
Under CTO Cody J. Phillips, PhD, Meridian has over a decade of specialized computer vision development. Dr. Phillips has published research in top conferences including CVPR, ICRA, RSS, and 3DV. He holds multiple patents in robotic vision systems. He also co-founded Avvir, which was acquired after Series B funding.
Dr. Phillips specializes in image metrology. This is the science of extracting precise measurements from visual data. He has applied this directly to putting's unique challenges:
Transparent edge detection (for tracking clear ball paths)
Shape reconstruction (understanding putter geometry)
Pose estimation (analyzing body mechanics)
Mobile motion analysis (real-time processing on smartphones)
This expertise shows up in solving problems that would stump general AI teams. For example, tracking a white golf ball against a light-colored green requires sophisticated algorithms. These can distinguish subtle variations in texture, shadow, and reflection that human eyes easily see. Standard computer vision systems often miss these details.
All of this processing happens in real-time on mobile devices. This eliminates the need for expensive cloud servers or dependencies on external AI services. This mobile optimization adds another layer of complexity. It requires a deep understanding of both the algorithms and the hardware constraints.
At Our Core, We Are a Computer Vision Company
Golf putting represents both a billion-dollar market opportunity and the best way to showcase our technology. As we systematically explore high-value adjacent markets, our technical capabilities transfer naturally. These include precise motion analysis, real-time mobile processing, and sophisticated measurement extraction. They apply to other areas where understanding human movement matters.
Our approach fundamentally transforms access to expert-level analysis. We democratize elite performance insights that were previously available only to professionals and major institutions. We use proprietary CV models to build products that make people safer, healthier, and more capable in pursuits that matter.
The platform advantage our computer vision expertise creates is significant. Each vertical we enter strengthens our core capabilities. This expands our market opportunity from golf's billions toward the broader $31.8B computer vision market.
The Bottom Line
As computer vision continues evolving, one lesson becomes clear. Not all computer vision is created equal. The technologies that reshape industries are built on foundations of scientific precision, technical mastery, and real-world complexity. These separate truly intelligent systems from basic recognition tools.
For those seeking to understand where artificial intelligence creates lasting competitive advantages, look beyond the headlines. Focus on the sophisticated science of teaching machines not just to see, but to measure, understand, and act upon what they observe with human-like precision.